19/12/2019

Renat Není to poprvé, kdy autor host mluví o Layfhakere. Dříve jsme publikovali vynikající materiál od něj o tom, jak vytvořit tréninkový plán: hlavní kniha a on-line zdrojů, stejně jako inkrementální algoritmus vytvořit tréninkový plán.
Tento článek obsahuje některé jednoduché techniky, které pomáhají zjednodušit práci v Excelu. jsou zvláště užitečné pro ty zapojený do manažerského výkaznictví, připravuje různé analytické zprávy opírající se o přistání zpráv 1C a jiných forem těchto prezentací a diagramů vedení. Nepředstírám, že absolutní novinkou - v té či oné podobě, tyto metody jistě diskutována na fórech nebo uvedené v článku.
VLOOKUP (SVYHLEDAT) A PGR (HLOOKUP) fungují pouze v případě, že cílové hodnoty jsou v prvním sloupci nebo řádku tabulky, ze kterého chcete získat data.
V ostatních případech, existují dvě možnosti:

 Syntaxe možnosti:
Syntaxe možnosti:Úkol - k vyplnění buněk s hodnotami ve sloupci nahoře (v závislosti na postavení v každém řádku tabulky, a to nejen v prvním bloku řady knih na toto téma):
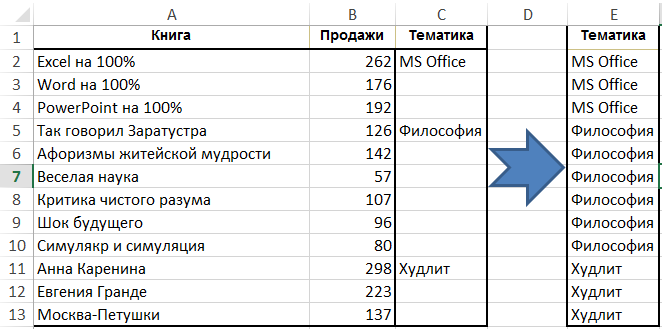
Vyberte sloupec „subjekt“, stisknutím tlačítka na pásce ve skupině tlačítko „Home“ v „Najít a zvolte» → «Označte skupinu buněk» → «Blank buňka „, a začít zadávat vzorec (tj dát rovnítko) a odkazuje na buňky, ze shora, pouhým stisknutím šipky nahoru klávesnice. Stiskněte klávesu Ctrl + Enter. Za to, že data mohou být uložena jako hodnota, protože vzorce jsou již nejsou potřeba:

Pro pochopení komplex vzorce (ve kterém jako argumenty funkce pomocí jiné funkce, to znamená, že některé funkce jsou uloženy v druhé), nebo najít v něm zdroj chyb, často potřebují k výpočtu její součástí. Existují dva jednoduché způsoby, jak:

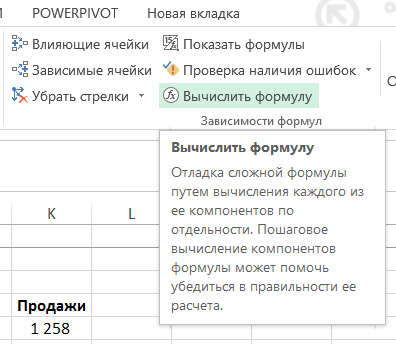

Chcete-li zjistit, které z buněk je závislá na vzorci ve skupině „vzorce“ v pásu karet klikněte na tlačítko „Trace precedentů“:

K dispozici jsou šipky ukazující, z nichž závisí výsledek.
Pokud je na vybraném snímku v červené barvě se objeví symbol, vzorec závisí na buňky, které jsou v jiných seznamech nebo v jiných knihách:

Kliknutím na něj, můžeme vidět, kde přesně vliv na buňku nebo oblast:
Vedle „Trace precedentů“ je tlačítko „příslušníci“, pracující stejným způsobem: zobrazí šipky z aktivní buňky se vzorcem s buňkami, které jsou na ní závislé.
Tlačítko „Odstranit šípy“ se nacházejí ve stejném bloku, umožňuje, aby se odstranily precedentů, rodinní příslušníci, nebo oba typy najednou šípů:
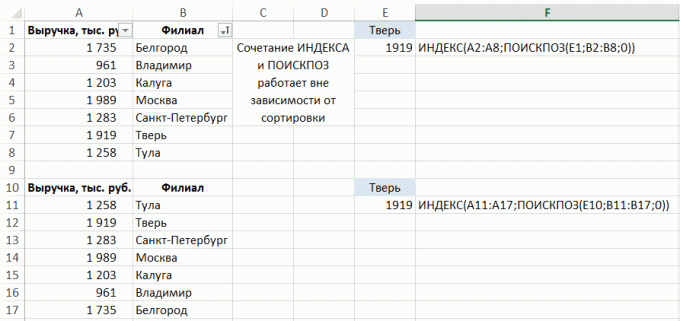
Řekněme, že máte několik podobný list s údaji, které chcete přidat, najít nebo zpracovány jiným způsobem:
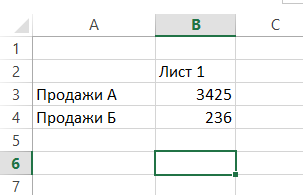
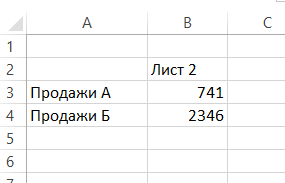
K tomu je buňka, ve které chcete vidět výsledek, zadejte standardní vzorec, jako například SUM (součet), a vstoupit argument následované dvojtečkou a příjmením prvního listu ze seznamu listů, které nemusí postup:
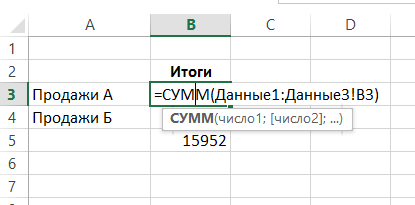
Obdržíte množství adres B3 buněk s listy „Data1“, „Data2“, „data3“:
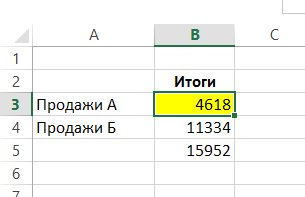
Takové adresování práce pro listy uspořádané postupně. Syntaxe je: feature = (pervyy_list: posledniy_list odkaz na rozsah!).
Použitím základní principy práce s textem v Excel a několika jednoduchými funkcemi, lze připravit stereotypní fráze pro hlášení. Některé principy práce s textem:
Příklad vytvoření šablony slova pomocí vzorce:

výsledky:

V tomto případě, kromě funkční symbol (znak) (zobrazit uvozovek) pomocí funkce KDYŽ (IF), který umožňuje změnit text v V závislosti na tom, zda se jedná o pozitivní trend v oblasti prodeje a funkce textu (text), umožňující zobrazení čísla v některém Formát. Jeho syntaxe je popsáno níže:
TEXT (hodnota; formát)
Tento formát je uveden v uvozovkách stejným způsobem, jako kdyby jste zadali vlastní formát v „Formát buněk“.
Můžete automatizovat složitější texty. Ve své praxi se automatizovat dlouhá, ale rutinní poznámky k účtům ve formátu „obr padl / růže Na XX o plánu především v důsledku zvýšení / snížení FAKTORA1 XX, zvýšení / snížení FAKTORA2 YY... »s měnící se seznamem faktory. Pokud píšete takové připomínky často a proces psaní může algoritmizace - hodnoty jednou zmatený vytvořit vzorec nebo makro, které vám ušetří alespoň z části práce.
Při kombinaci se buňky zachovány pouze jednu hodnotu. Excel vás upozorní při pokusu o sloučení buněk:
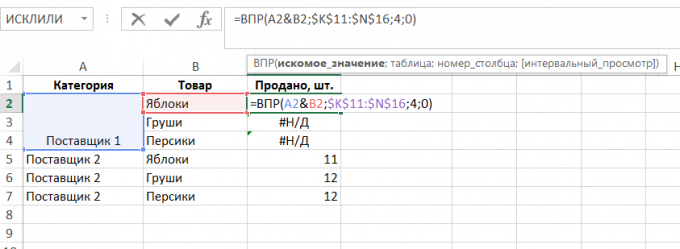
V souladu s tím, pokud byste měli vzorec, který je závislý na každou buňku, bude to přestane fungovat po svém unie (bug # N / A v řadách 3-4 příklady):
Chcete-li sloučit buňky, při zachování dat v každé z nich (možná máte vzorec, jako v tomto případě, abstraktní; budete chtít sloučit buňky, ale zachovat všechna data v budoucnosti, nebo se skrýt své záměry), kombinovat jakoukoliv buňku list, vyberte je a pak použijte formát příkaz „Kopírovat formát“ přenosu na buňky, které budete potřebovat a kombinovat:

Pokud potřebujete vytvořit konsolidovaný z více zdrojů dat, je nutné přidat k pásku nebo na panel nástrojů Rychlý přístup „kontingenční Wizard a grafy“, ve kterém existuje taková možnost.
To lze provést následujícím způsobem: „File» → «Nastavení» → «Panel nástrojů Rychlý přístup» → «All tým» → «kontingenční Wizard a diagramy» → «Přidat»:

Poté bude páska se odpovídající ikona, kliknutím na který způsobí, že přidání master:

Když na něj kliknete, dialogové okno:
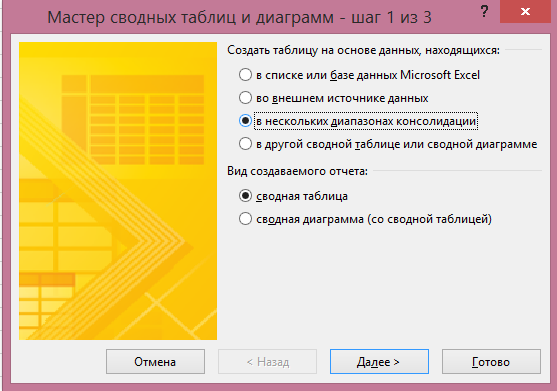
V něm budete muset vybrat „Pár kapel konsolidace“ a klikněte na tlačítko „Další“. V další části si můžete vybrat „Vytvoření jednoho pole stránky“ nebo „Vytvořit pole stránky.“ Pokud se chcete sami přijít s názvem pro každý ze zdrojů dat - zvolte druhou položku:

V dalším okně, přidat všechny rozsahy na základě nichž lze stavět shrnutí, a zeptejte se jich jména:

Po tomto bodě, bude hostit kontingenční tabulky v posledním dialogovém okně - na stávající nebo nového listu:
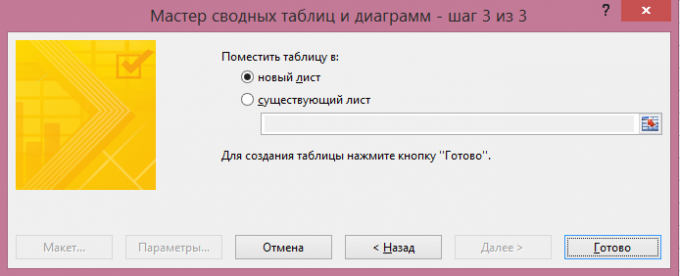
Zpráva kontingenční připraven. Filtr „Page 1“ můžete vybrat pouze jeden ze zdrojů dat, je-li to nutné:
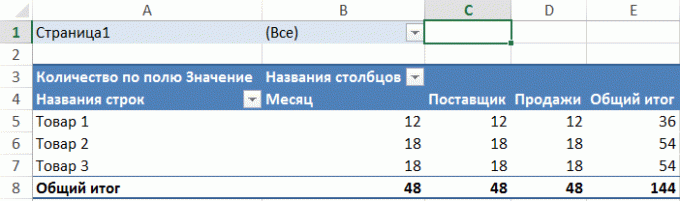
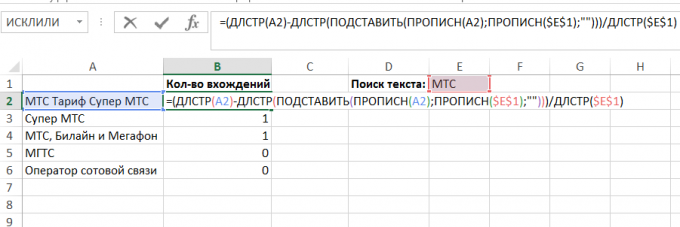
V tomto příkladu, ve sloupci A, existuje několik řádků textu, a naším úkolem - zjistit, kolikrát každý z nich splňuje požadovaný text v buňce E1:
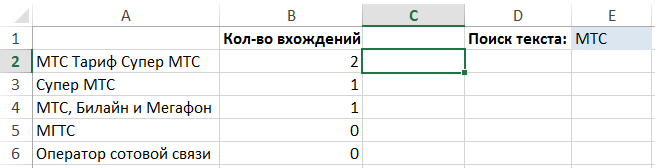
Chcete-li tento problém vyřešit, můžete použít složitý vzorec skládající se z následujících funkcí:
Chcete-li najít určitý vstup textového řetězce do druhého, je nutné odstranit všechny jeho výskyty v originále a porovnat délku řetězce od originálu:
LEN ( "Tarif Super MTS MTS") - LEN ( "Super Rate") = 6
A pak rozdělí rozdíl podle délky trati, jsme hledali:
6 / LEN ( "MTS") = 2
To je dvakrát řádku „MTS“ je v originále.
To zbývá být napsány v jazyce algoritmu vzorců (označenou „text“ je text, který se snažíme vstup a „žádoucí“ - počet výskytů, že máme zájem o):
= (LEN (text) -DLSTR (náhražka (horní (text) UPPER (vyhledávaná); ""))) / LEN (vyhledávaná)
V našem příkladu vzorec je následující:
= (LEN (A2) -DLSTR (náhražka (horní (A2), UPPER ($ E $ 1); ""))) / LEN ($ E $ 1)