19/12/2019

Batyanov Denis o právech autora hodnocení vysvětluje v tomto příspěvku o tom, jak najít data v jednom Excel a extrahovat do druhého, a zjišťuje, všechna tajemství vertikální funkce sledování.
Při práci v vynikat Velmi často je potřeba najít data v tabulce a odstranit je na druhou. Pokud si nevíte, jak to udělat, pak jsem si přečetl článek, budete nejen učit, ale také zjistit, za jakých podmínek bude moci vytlačit maximální výkon systému. Považováno za nejvíce vysoce účinné metody, které by měly být použity ve spojení s funkcí CDF.
Dokonce i když máte letech používání funkce CDF, s velkou pravděpodobností tento článek bude užitečné pro vás a nenechá lhostejným. Já, například, jak IT specialista, a pak lídr v oblasti IT, který se používá funkce SVYHLEDAT 15 let, ale Vypořádat se všemi nuancemi se stalo právě, když jsem na profesionální bázi jsem začal učit lidé Excel.
CDF - zkratka vvertikální, atd.inspekce. Podobně, VLOOKUP - vertikální vyhledávání. Samotný název funkce naznačuje nám, že hledá řádky tabulky (vertikální - třídící linky a upevnění osy), a nikoli ve sloupci (horizontální - seřazením sloupců a upevnění line). Je třeba poznamenat, že CDF má sestru - Ošklivé káčátko, které se nikdy nestane labuť - je závislá na PGR (VVYHLEDAT). PGR, na rozdíl od CDF, vytváří horizontální vyhledávání, ale koncept Excel (a opravdu konceptu organizovat data) znamená, že vaše tabulky mají malý počet sloupců a mnoho dalších linky. To je důvod, proč hledání řetězce, jsme víc než sloupců je třeba mnohokrát. pokud se vám
vynikat Až příliš často používají VVYHLEDAT, to je docela pravděpodobné, že tam je něco, co nechcete pochopit, v tomto životě.SVYHLEDAT má čtyři parametry:
PPS = (
Vsadím se, že mnozí z těch, kteří znají funkci CDF jako peeling, přečtěte si popis čtvrtý parametr může cítit nepříjemně, protože používá ho vidět v mírně odlišným způsobem: obvykle je zde řeč o přesném souladu s hledáním (nepravda nebo 0), nebo o stejném zorném poli (TRUE nebo 1).
Nyní je třeba, aby zpřísnila a přečíst další odstavec několikrát, až se dostanete pocit pro smyslu toho, co bylo řečeno, až do konce. Tam je každé slovo důležité. Příklady pomůže pochopit.

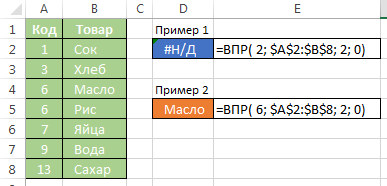


Pokud je zjištěno, že hodnota v prvním sloupci matice několikrát, bude vzorec zvolit první řádek pro pozdější použití.
Jste dosáhli vrcholu v místě článku. Mohlo by se zdát, dobře, v čem je rozdíl, jestli bych poukázat na to jako poslední parametr nula nebo jedna? V podstatě celý bod, samozřejmě nula, protože to je docela praktické: není třeba se obávat třídění první sloupec matice, jeden může vidět, našel hodnotu, nebo ne. Ale pokud máte seznam několika tisíc vzorců CDF (SVYHLEDAT), všimnete si, že typ CDF běží II pomalu. To je obvykle všechno začalo přemýšlet:
A jen málo lidí si myslí, že jakmile začnete CDF typu I a zajistit nějaký způsob, jak třídit první sloupec jako rychlost operace CDF zvýší 57 krát. Píšu slova - za padesát sedmkrát! V 57% a 5700%. Tato skutečnost Ověřil jsem si docela spolehlivě.
Tajemství těchto rychlých práce spočívá v tom, že můžete použít na tříděném poli je nesmírně efektivní vyhledávací algoritmus, který je známý jako metoda binární vyhledávání (bisekce, dichotomie). Tak nějak jsem CDF používá ho, a typ CDF II usiluje bez optimalizace obecně. Totéž platí pro zápasu (Match), který obsahuje stejný parametr, a také na funkci SLEDOVÁNÍ (LOOKUP), který lze použít pouze u tříděných polí a aktivován v Excelu pro kompatibilitu s Lotus 1-2-3.
Nevýhody CDF jsou zřejmé: nejprve se snaží pouze první sloupec tohoto pole, a za druhé, právě napravo od tohoto sloupce. A jak víte, může se stát, že sloupec, který obsahuje potřebné informace v levé části kolony, ve které se snažíme. Postrádající tento nedostatek již bylo zmíněno spoustu vzorců INDEX + MATCH (INDEX + MATCH), který se nejvíce flexibilní řešení pro extrakci dat z tabulky ve srovnání s CDF (SVYHLEDAT) dělá.
Klasický obrázek o rozsahu vyhledávání - problém stanovení velikosti slev řádu.

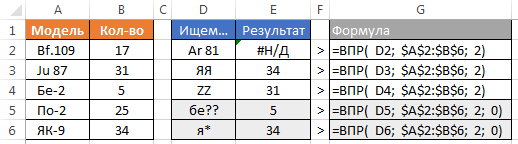
Samozřejmě, že CDF usiluje nejen čísla, ale i text. Je třeba mít na paměti, že malá a velká písmena formule nerozlišuje. Pokud použijete zástupné znaky, je možné uspořádat fuzzy vyhledávání. Existují dva zástupné znaky „?“ - nahrazuje libovolný znak v textovém řetězci „*“ - nahrazuje libovolný počet jakýchkoliv znaků.
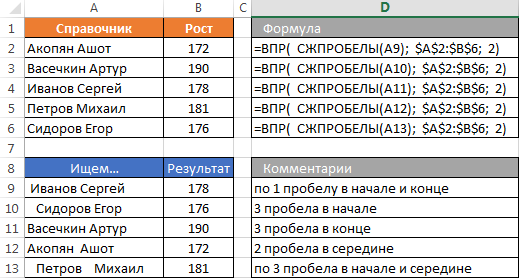
Často vyvstává otázka, jak vyřešit problém dodatečných prostorů v hledání. Pokud je v tabulce look-up je stále možné je čistit, první parametr vzorce CDF není vždy záviset na vás. Z tohoto důvodu, pokud je riziko ucpání buňkám více prostoru je k dispozici, je možné použít funkci TRIM (TRIM) za účelem čištění.
V případě, že první parametr funkce CDF se týká buňky, která obsahuje číslo, ale který je uložen v buňky jako text, a první sloupec matice obsahuje čísla ve správném formátu, bude vyhledávání mít neúspěšné. Obrácená situace. Problém je snadno vyřešit parametrem převodu 1 do požadovaného formátu:
PPS = (- D7; Produkty $ A $ 2: $ C $ 5;! 3; 0) - pokud D7 obsahuje text a tabulky - čísla;
= CDF (D7 & «»); Produkty $ A $ 2: $ C $ 5;! 3; 0) - a naopak.
Mimochodem, přeložit text v řadě může být několik způsobů, vyberte:
Překlad textu vyrábí kopulací s prázdný řetězec, který způsobuje Excel převést datový typ.
To je velmi výhodné co do činění s funkcí IFERROR (IFERROR).
Například: = IFERROR (CDF (D7; Produkty $ A $ 2: $ C $ 5;! 3; 0); «»).
V případě, že CDF vrátí kód chyby # N / A, pak se zachytí IFERROR náhradu a parametr 2 (v tomto případě, prázdný řetězec), a Pokud nedošlo k žádné chybě, bude tato funkce předstírat, že to není vůbec, ale jen CDF, obnoveny k normálu vyplývat.
Často přehlížena referenci uskupení je vytvořeno absolutní, a když se táhne celou řadu „plave“. Uvědomte si, že místo toho, A2: C5 by měly být použity $ $ 2: $ C $ 5.
Dobrý nápad je umístit referenční pole na samostatném listu v sešitu. To nedostane pod nohama, a bude mít uloženy.
Ještě dobrý nápad vyhlášením pole jako pojmenované oblasti.
Mnoho uživatelů se používají při určování struktury typu pole A: C, což ukazuje sloupce úplně. Tento přístup má právo na existenci, protože jste ušetřeni nutnosti udržení přehledu o tom, že vaše pole obsahuje všechny nitky. Máte-li přidat řádek na kus původního pole, rozsah specifikován jako A: C, nebudou muset přizpůsobit. Samozřejmě, tato syntaxe způsobí Excel strávit trochu víc práce, než s přesným údajem o rozsahu, ale data režie je zanedbatelný. Řeč je o setin sekundy.
No, na pokraji génia - k problému v podobě matice smart stolek.
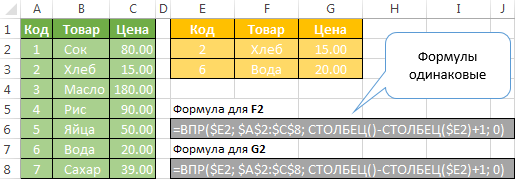
V případě, že tabulka, do kterého extrahovat data pomocí CDF, má stejnou strukturu jako tabulky look-up, ale jen obsahuje minimální počet řádků v WRT domény mohou být použity sloupcové funkce () pro automatické výpočet počtu nahraditelných sloupy. V tomto případě všechny CDF-formule bude stejná (očištěno o první parametr, který automaticky změní)! Všimněte si, že první parametr je absolutní souřadnice kolony.
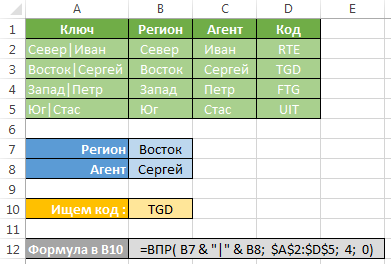
Pokud je potřeba podívat se na více než jednom sloupci najednou, je nutné, aby se složený klíč pro vyhledávání. V případě, že vrácená hodnota není Text (jak je zde v případě pole „kód“), a numerický, pro Toto přišlo do vhodného vzorce SUMIFS (SUMIFS) a integrální sloupci klíč by nemělo být požadováno vůbec.
Tohle je můj první článek na Layfhakera. Pokud se vám to líbilo, a pak vás zvu na návštěvu můj webA rád četl vaše komentáře o tajemství pomocí funkce SVYHLEDAT a podobně. Děkuju. :)